Wayback Machine APIでドメインの調べ方
ドメインの履歴をチェックする際、Wayback Machine APIを使用すれば、ブラウザのみで簡単に調べることができます。
使い方は、以下のURLにクエリを指定してアクセスするだけです。
https://web.archive.org/cdx/search/cdx?url=例えば、当ブログは「blog-tips.net/blog/」なので、以下のようにアクセスします。
https://web.archive.org/cdx/search/cdx?url=blog-tips.net/blog/そうしますと、以下の結果が表示されますが、2009年6月4日1時57分13秒に最初にデータが保存されたことがわかります。
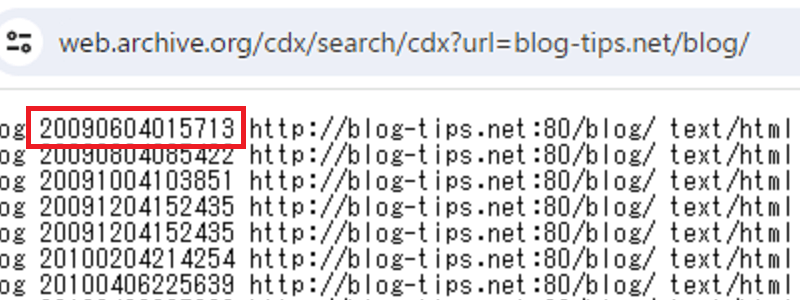
通常のWayback Machineでチェックすると、ウェブページの過去のキャプチャを閲覧することができますが、こちらのAPIではサイト自体は表示されないため、表示が速く、サクサク調べることができます。
デフォルトでは「exact」なので、そのURLのみが表示されます。一方、「&matchType=prefix」などとパラメータを指定すると、そのURL以下の前方一致で保存されているすべてのURLが表示されます。ただし、この場合は膨大な量となってしまうため、「&limit=200」などと、表示数に制限をかけてアクセスします。
https://web.archive.org/cdx/search/cdx?url=blog-tips.net/blog/&matchType=prefix&limit=200さらに、上記の場合、個別ページの年月に応じた重複のデータが表示されてしまいます。当ブログでいいますと、アルファベット順のA行のarchives.htmlページだけで50個ほど表示されますが、「&collapse=urlkey」で重複を除外して最初の保存データのみを表示させれば、全てのページのデータを表示させることができます。
https://web.archive.org/cdx/search/cdx?url=blog-tips.net/blog/&matchType=prefix&limit=200&collapse=urlkey加えて、さらに上記の場合、画像などもヒットしてしまうため、「&filter=mimetype:text/html」でHTMLページのみでフィルタをかけると以下のようになります。
https://web.archive.org/cdx/search/cdx?url=blog-tips.net/blog/&matchType=prefix&limit=200&collapse=urlkey&filter=mimetype:text/htmlさらに、「&fl=timestamp,urlkey,original」などと指定して、表示項目をタイムスタンプやURLのみで制限してスッキリ表示させることもできます。
https://web.archive.org/cdx/search/cdx?url=blog-tips.net/blog/&matchType=prefix&limit=200&collapse=urlkey&filter=mimetype:text/html&fl=timestamp,urlkey,originalこの項目には、以下の"URL", "時刻", "オリジナルURL", "MIMEタイプ", "ステータスコード", "一意の識別コード", "サイズ"がありますので、必要な項目だけ、カンマで表示させればよいと思います。
["urlkey","timestamp","original","mimetype","statuscode","digest","length"]
また、データのサイズ量が大幅に変更になっている場合には、ドメインの所有者が変更になった可能性が高いです。
そのほか、&from=2009&to=2010などと期間を区切って表示させることもできます。
PythonでHTTPリクエストでデータを取得することもできますが、上記の方法ですと、ブラウザからcdxサーバーにアクセスすればいいだけなので簡単に利用することができます。
ちなみに、Wayback Machineはインターネットアーカイブが運営する様々なサービスのうちの1つです。インターネットアーカイブのAPIにも様々ありますが、ウェブページのキャプチャに関しては、Wayback Machine APIを使用した方が使いやすいと思います。