pythonのクローラーを拒否してみました
今月に入ってから「python」というクローラーのアクセスが頻繁になってきたため、このロボットのアクセスは拒否することにしました。
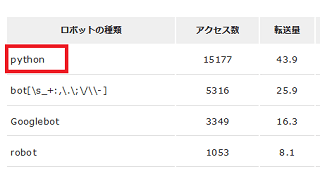
別のサイトでも同様でした。

どのクローラーでも特に拒否するつもりはないのですが、Googleボットの5倍の大量アクセスとなると尋常ではなく、ある意味でDoS攻撃に近いものがあると思います。最近どうもサイトが重いと感じていたのですが、おそらくはこれが原因ではないかと思います。
サーバーのアクセスログで詳細を確認してみたところ、このクローラーは日本国内のIPアドレスでawsを使っているようです。
おそらくコンテンツの自動収集によるスクレイピングを目的にやってきていると思いますので、拒否しても特に何の影響もないと思います。むしろ、サイトが軽くなってSEO対策上のメリットがあるかもしれません。
拒否をする具体的な方法については省略しますが、htaccessにUser-Agentでpythonを指定して、Allow from all Deny fromで記載するか、もしくはrobots.txtにdisallowで記載しておけばよいでしょう。
そのほか、SEO関係の「AhrefsBot」や「DotBot」、「MJ12bot」などのクローラーも拒否してもいいと感じてますが、これらは悪意がないですし、それほど大量のアクセスではないため無視できる範囲かと思います。
基本的に、紳士的なクローラーは以下のように参照元のURL付きで身元を名乗った上でアクセスしてきます。
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
こういうのは大体は問題ないかと思いますが、何の目的なのかよく分からないクローラーについては拒否しておいても特に問題はないでしょう。